



Optimiser une requête SQL, ce n’est pas seulement “aller plus vite”.
C’est garantir la stabilité, la scalabilité et la prévisibilité du système — surtout quand la donnée explose.
Une requête mal structurée, un index oublié ou une jointure douteuse peuvent suffire à dégrader une application entière.
Voici une version complète, technique et réaliste, pensée pour les développeurs et architectes qui veulent écrire du SQL qui scale.
Maîtriser l’indexation : ton premier levier de performance
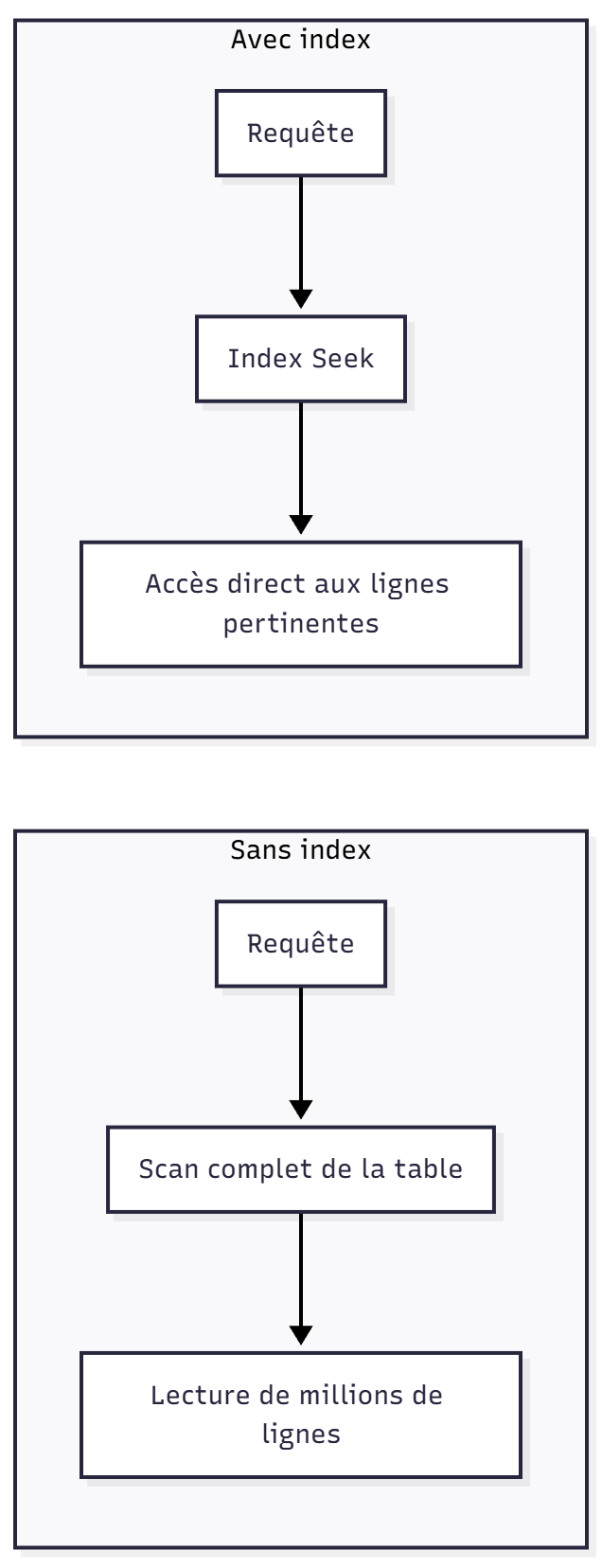
Les index sont les fondations de toute optimisation. Sans eux, la base scanne tout. Avec eux, elle cible immédiatement les données utiles.
Exemple (PostgreSQL)
SELECT *
FROM orders
WHERE customer_email = 'john@doe.com';Sans index, PostgreSQL parcourt toute la table (table scan).
Avec index :
CREATE INDEX idx_orders_customer_email ON orders(customer_email);Erreurs fréquentes
- Indexer des colonnes non sélectives (
status,is_active) - Multiplier les index “au cas où”
- Mauvais ordre dans les index composés
Index couvrant (SQL Server)
CREATE NONCLUSTERED INDEX idx_sales_reporting
ON sales (customer_id)
INCLUDE (amount, sale_date);La requête suivante devient ultra rapide :
SELECT customer_id, amount, sale_date
FROM sales
WHERE customer_id = 42;Jointures : là où la moitié des problèmes commencent
Exemple classique qui tue les performances :
SELECT *
FROM Users u
JOIN Orders o ON u.name = o.customer_name;Jointure textuelle → lente, peu sélective, non indexée.
Version propre :
SELECT *
FROM Users u
JOIN Orders o ON u.id = o.user_id;Avec :
CREATE INDEX idx_orders_userid ON Orders(user_id);Conseils :
- Joindre uniquement sur une clé
- Indexer les colonnes de jointure
- Ne sélectionner que les colonnes pertinen
Ne jamais utiliser SELECT *
SELECT * charge inutilement des colonnes, parfois volumineuses.
SELECT * FROM products LIMIT 50;→ 200 colonnes, 50 JSONB… alors que l’écran affiche 3 champs.
Version propre :
SELECT id, name, price
FROM products
LIMIT 50;WHERE : écrire des filtres qui utilisent les index
Éviter les transformations sur les colonnes indexées.
Mauvais
WHERE DATE(created_at) = '2025-01-01'Bon
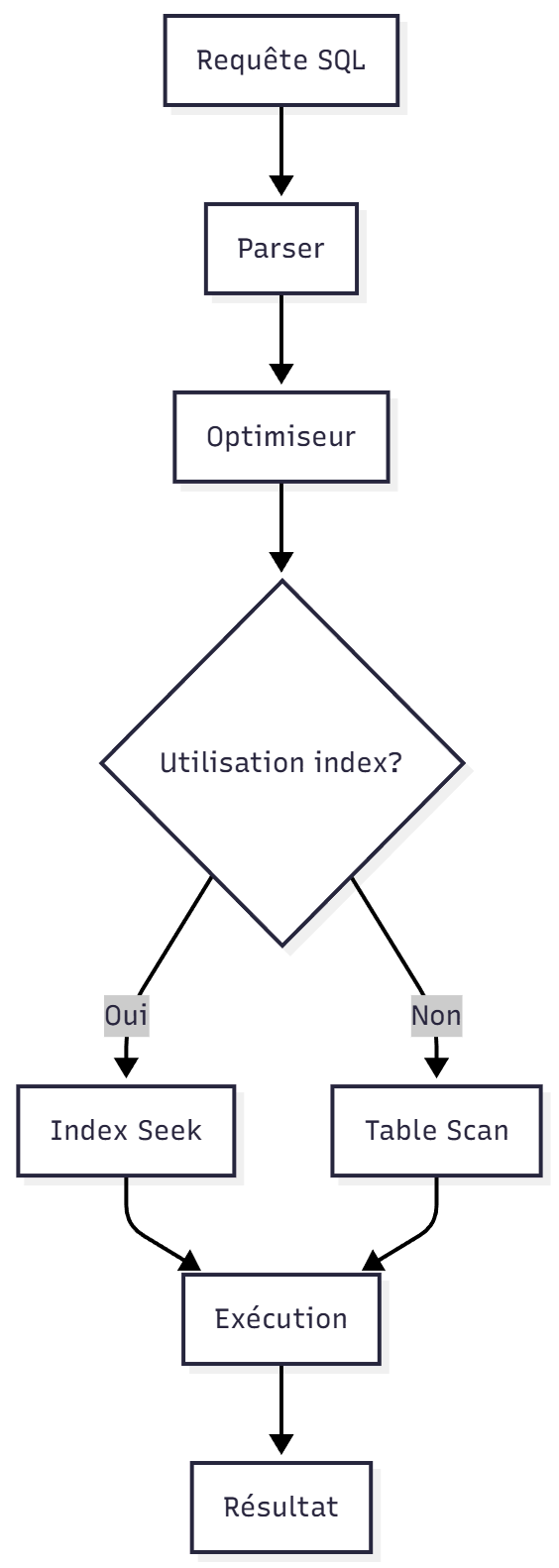
WHERE created_at BETWEEN '2025-01-01' AND '2025-01-02'Lire un plan d’exécution : obligatoire
Commandes utiles :
PostgreSQL
EXPLAIN ANALYZE SELECT …SQL Server
SET STATISTICS IO ON;
SET STATISTICS TIME ON;Points à surveiller :
- Table Scan
- Nested Loop non contrôlé
- Hash Join inutile
- Rows estimées vs réelles
Si l’estimation diffère fortement du réel :
→ problème d’index, statistiques obsolètes, mauvais prédicat.
CTE et factorisation : rendre les grosses requêtes lisibles et optimisables
Mauvais :
SELECT *
FROM orders
WHERE customer_id IN (SELECT id FROM customers WHERE active = true);Bon :
WITH active_customers AS (
SELECT id FROM customers WHERE active = true
)
SELECT o.*
FROM orders o
JOIN active_customers ac ON ac.id = o.customer_id;Transactions : courtes, atomiques, prévisibles
Plus une transaction dure, plus elle bloque le système.
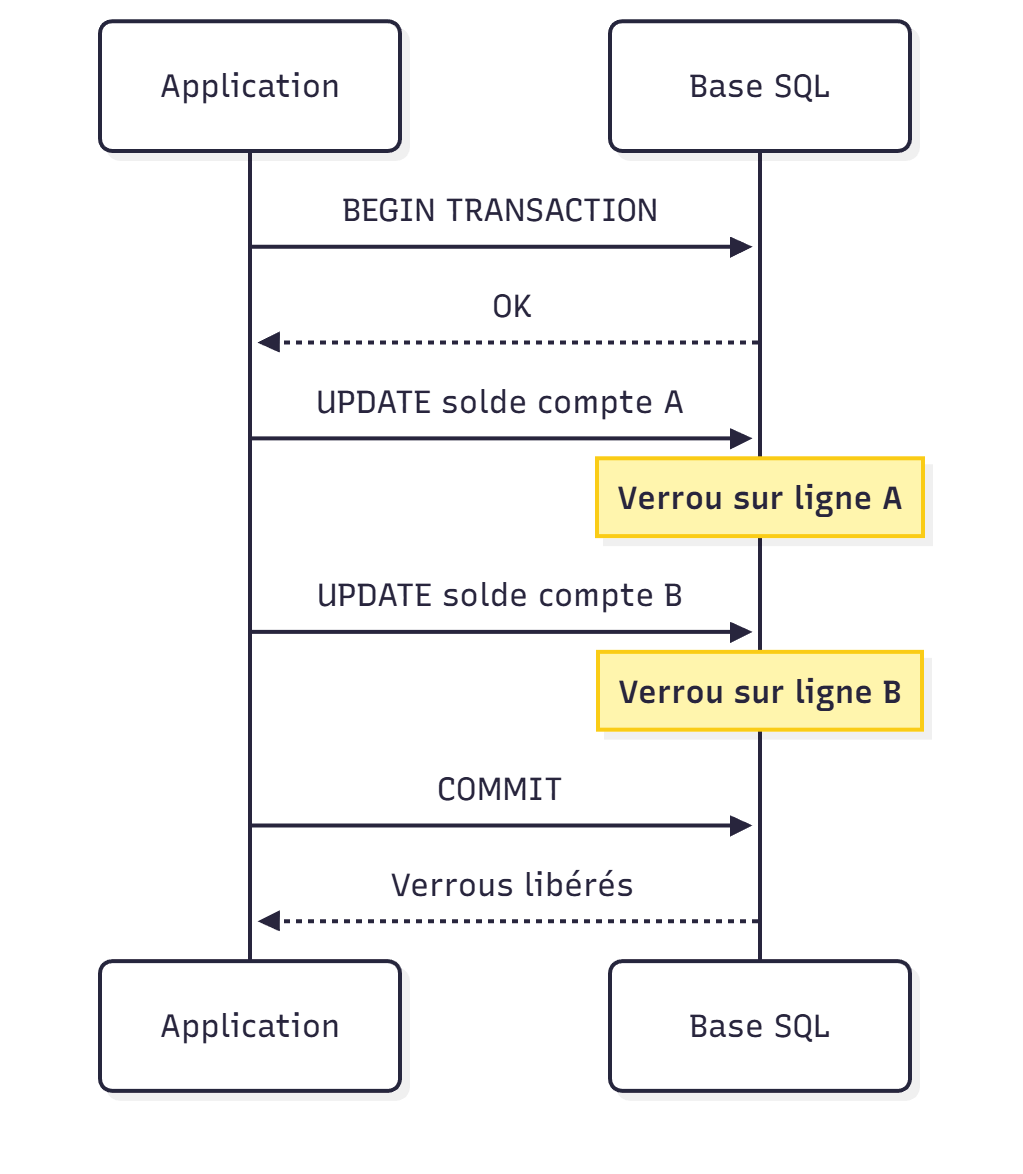
Exemple toxique
BEGIN TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
WAITFOR DELAY '00:00:05';
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;
Version correcte :
BEGIN;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;Partitionnement : indispensable dès plusieurs dizaines de millions de lignes
Exemple PostgreSQL :
CREATE TABLE logs_2025 PARTITION OF logs
FOR VALUES FROM ('2025-01-01') TO ('2026-01-01');Une requête du type :
SELECT * FROM logs WHERE created_at >= NOW() - INTERVAL '1 day';Tables temporaires & variables (SQL Server)
Table temporaire
CREATE TABLE #t (id INT, total DECIMAL(10,2));
INSERT INTO #t
SELECT id, SUM(amount)
FROM sales
GROUP BY id;Variable table
DECLARE @t TABLE (id INT, total DECIMAL(10,2));Règle simple :
- < 1000 lignes → variable ok
- 1000 lignes → table temporaire
Normalisation vs dénormalisation : le vrai équilibre
La normalisation apporte la cohérence.
La dénormalisation apporte la vitesse.
Pour un dashboard :
calc temps réel = lourd
pré-agrégation = instantané
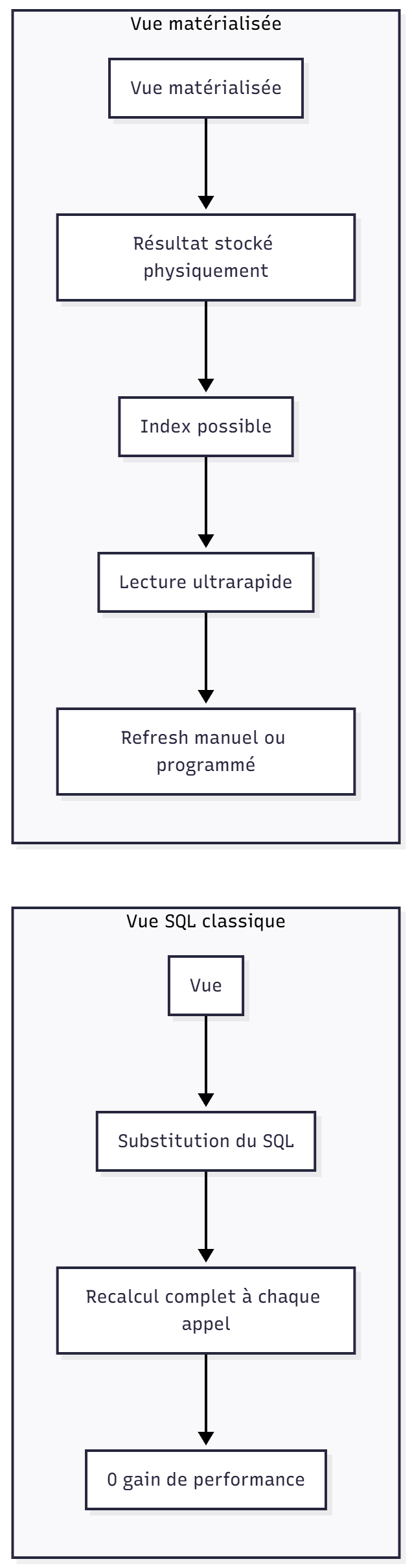
Views : abstraction utile, mais 0 impact sur les performances
C’est l’une des confusions les plus fréquentes :
Non, une vue SQL n’améliore pas les performances.
Une vue classique :
- ne stocke rien
- n’a pas d’index propre
- est réécrite à chaque exécution
- est recalculée intégralement
Elle n’est qu’une abstraction, une manière propre de structurer une requête complexe, et un excellent outil de gouvernance (exposer un modèle de lecture sans donner accès aux tables sous-jacentes).
Exemple : vue classique (ré-exécutée)
CREATE VIEW v_orders_enriched AS
SELECT o.id, o.date, c.name, c.country, p.total
FROM orders o
JOIN customers c ON c.id = o.customer_id
JOIN payments p ON p.order_id = o.id;Requête :
SELECT * FROM v_orders_enriched WHERE country = 'FR';→ La vue est substituée dans le plan d’exécution.
Aucun gain de performance.
Vue matérialisée : la seule vue qui accélère les performances
La materialized view stocke physiquement le résultat.
C’est un cache SQL, indexable, stable, rapide.
Exemple PostgreSQL
CREATE MATERIALIZED VIEW mv_sales_daily AS
SELECT date_trunc('day', created_at) AS day,
SUM(amount) AS total
FROM sales
GROUP BY day;Lecture instantanée :
SELECT * FROM mv_sales_daily;Rafraîchissement :
REFRESH MATERIALIZED VIEW mv_sales_daily;Version non bloquante :
REFRESH MATERIALIZED VIEW CONCURRENTLY mv_sales_daily;Changer de mindset : penser ensembliste, pas procédural
Écrire du SQL performant, c’est aussi changer sa manière de réfléchir.
La plupart des développeurs abordent les requêtes avec un mindset procédural : ils imaginent une boucle, un traitement ligne à ligne, et une exécution dans l’ordre exact du code.
Mais un moteur SQL fonctionne en pensée ensembliste :
- Tu décris l’ensemble que tu veux obtenir
- Le moteur choisit comment l’obtenir
- L’ordre d’écriture n’a rien à voir avec le plan réel
- Le moteur optimise en fonction du coût global, pas de la logique textuelle
Ce changement de paradigme est clé.
On n’optimise pas une requête en “réorganisant” son texte.
Au fond, optimiser une requête revient toujours à la même idée : réduire la taille des ensembles que le moteur doit manipuler.
Tout se joue dans la capacité à guider l’optimiseur vers le chemin le plus court, celui où il lit moins de données, traverse moins de pages, et ne se perd pas dans des plans coûteux.
Cela passe par une structure de données pensée pour être filtrée rapidement, des jointures capables de relier les ensembles de manière cohérente, une organisation logique du stockage qui permette au moteur de cibler immédiatement les zones pertinentes, et une façon d’écrire les requêtes qui laisse le moteur exploiter pleinement son modèle ensembliste.
Parfois, cela implique de préparer une partie du travail en amont, en pré-agrégeant ou en matérialisant certains résultats pour éviter des recalculs coûteux.
Le moteur gagne alors en efficacité, non pas parce qu’on lui dit “comment faire”, mais parce qu’on lui donne les conditions idéales pour choisir la meilleure stratégie.
Quand tu penses “ensembles” plutôt que “procédure”, tu écris du SQL qui scale, qui reste stable sous charge, et qui tient en production.


