



L’intégration d’un LLM dans une application n’est pas qu’une affaire de prompt. Dès que l’on quitte l’expérimentation pour construire un vrai produit, il faut retrouver les réflexes d’architecture logicielle. Le modèle devient un service à part entière : il s’oriente, il se contraint, il s’intègre, et il doit répondre de manière prévisible.
Le développement local avec Ollama met encore plus en évidence cette discipline. On peut profiler le modèle, versionner son environnement, tester les flux comme on teste un service métier. L’IA s’intègre dans l’écosystème, elle n’est plus une magie externe.
Le Pattern Intent Router
Dans une architecture API, le point d’entrée unique facilite le contrôle.
Le client appelle toujours /ask, et c’est le router qui décide de la suite. Le LLM ne reçoit pas une question “brute” mais un message JSON structuré indiquant ce que l’utilisateur veut faire.
Endpoint /ask
app.MapPost("/ask", async (AskRequest request, IntentRouter router) =>
{
var result = await router.RouteAsync(request);
return Results.Json(result);
});Analyse de l’intention par le LLM
public async Task<string> ExtractIntent(string userPrompt)
{
var scaffold = new
{
instruction = "Détermine l'intention utilisateur. Réponds uniquement avec un mot clé.",
input = userPrompt
};
var response = await _ollama.GenerateJsonAsync(scaffold);
return response["intent"].GetValue<string>();
}Le modèle ne choisit pas l’action finale, il identifie simplement l’intention et l’application reste souveraine.
Le Pattern DSL Prompting
Plutôt que d’imposer un pseudo-langage textuel, on utilise une structure JSON stricte passée via /ask.
Cela réduit dramatiquement les ambiguïtés et s’intègre naturellement dans des workflows API.
Requête envoyée au backend
POST /ask
{
"action": "summarize",
"payload": {
"topic": "l'évolution de .NET",
"length": "short",
"format": "markdown"
}
}Prompt interne généré pour Ollama
{
"instruction": "Tu génères un résumé structuré selon les paramètres fournis.",
"rules": {
"length": "short|medium|long",
"format": "markdown|text"
},
"input": {
"topic": "l'évolution de .NET",
"length": "short",
"format": "markdown"
}
}Côté C#
public async Task<string> SummarizeAsync(SummaryPayload payload)
{
var prompt = new
{
instruction = "Génère un résumé strictement structuré.",
rules = new { },
input = payload
};
var result = await _ollama.GenerateMarkdownAsync(prompt);
return result;
}Le modèle n’improvise pas, il remplit un contrat JSON.
Le Pattern Tooling
Les outils exposés au modèle deviennent des actions internes de l’API comme récupérer la météo, lire un utilisateur en base, appeler un service externe.
Le LLM ne fait que demander l’outil via un JSON normalisé et le backend exécute.
L’IA décide, l’API exécute, et rien n’est laissé au hasard.
Prompt interne :
{
"instruction": "Si l'utilisateur parle d'un profil, appelle l'outil get_user.",
"input": "Donne-moi les infos pour l'utilisateur jean@example.com",
"tools": [
{ "name": "get_user", "schema": { "email": "string" } }
]
}Le modèle renverra :
{
"tool_call": "get_user",
"arguments": { "email": "jean@example.com" }
}Côté C# :
if (response.ToolCall == "get_user")
{
var email = response.Arguments["email"].GetValue<string>();
return await _db.Users.FirstAsync(u => u.Email == email);
}Le Pattern Memory
La mémoire n’est pas un vague historique, c’est un store structuré, consultable via le EndPoint /session/{id}/memory.
Le modèle s’appuie sur des données réelles, jamais sur une “intuition”.
Stockage
public async Task SaveMemoryAsync(string sessionId, LlmMemory memory)
{
await _db.Memories.UpsertAsync(new MemoryRecord(sessionId, memory));
}Réinjection dans les prompts
À chaque appel /ask, on recharge le contexte :
var memory = await _memory.LoadAsync(request.SessionId);
var prompt = new
{
instruction = "Tiens compte du contexte conversationnel fourni.",
memory,
input = request.Payload
};Le Pattern Guardrail
Sortie non conforme → rejet immédiat.
L’API joue le rôle de pare-feu.
Validation JSON stricte
var isValid = JsonValidator.ValidateSchema(response, summarySchema);
if (!isValid)
{
return Results.BadRequest(new { error = "Réponse non conforme" });
}Les guardrails transforment une IA bavarde en un service fiable.
Le Pattern Multi-Pass
Pour améliorer la qualité de la réponse, le backend enchaîne plusieurs passes vers le modèle.
Tout passe toujours par l’unique endpoint /ask, mais en interne, l’API orchestre plusieurs séquences.
Exemple pour la création de contenu :
var plan = await _ollama.GenerateAsync(new { step = "plan", input = req });
var draft = await _ollama.GenerateAsync(new { step = "draft", plan });
var final = await _ollama.GenerateAsync(new { step = "refine", draft });Le client ne voit qu’un appel et le backend orchestre trois passes.
Le Pattern Deterministic Output
Quand l’API doit exploiter la sortie immédiatement, on impose au modèle un format stable.
Contrat JSON exigé par le LLM
{
"summary": "string",
"keywords": ["string"],
"score": "number"
}Parsing fiable côté C#
var dto = JsonSerializer.Deserialize<StructuredSummary>(rawResponse);Avec un protocole clair, nous avons zéro surprise.
Architecture (API .NET + Ollama)
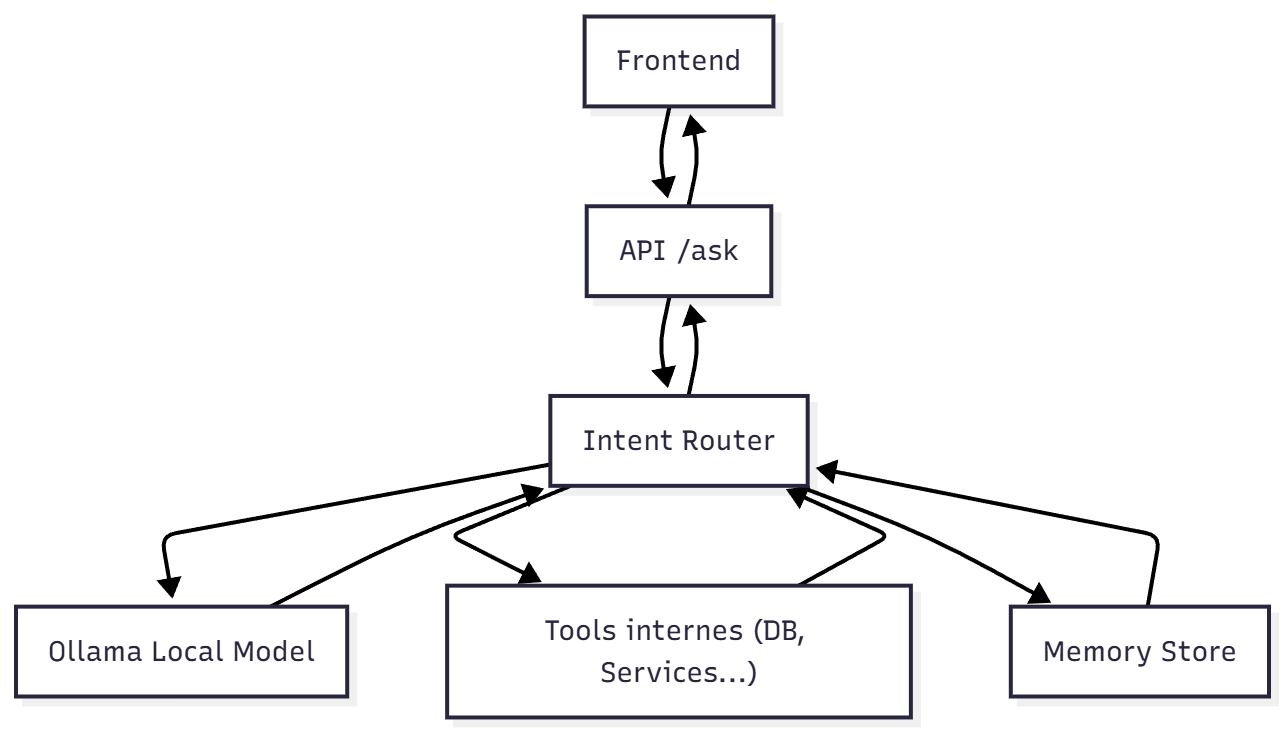
Tout converge vers /ask. C’est le cerveau qui organise, pas le modèle.
Un développement IA réellement maîtrisé
Avec un LLM local, une API .NET et un point d’entrée unique, l’IA devient un service maîtrisé :
un flux propre, guidé, déterministe, intégrable comme n’importe quel composant applicatif.
Ces patterns ne sont pas théoriques ; ils sont opérationnels. Ils permettent de construire une plateforme IA robuste, testable, prédictible, adaptée à la production.


