



Quand LLM et systèmes distribués rendent la décision inexplicable
Pendant longtemps, l’ingénierie logicielle a reposé sur une promesse implicite. Même dans les systèmes les plus complexes, même au cœur de monolithes difformes ou de microservices mal découpés, il existait toujours une chaîne causale. Un incident finissait par raconter une histoire. Une règle métier mal comprise. Un appel HTTP inattendu. Un message perdu. Un commit. Un humain.
Les systèmes distribués ont déjà mis cette promesse sous tension. L’asynchronisme, l’éventual consistency, les retries silencieux, les caches invisibles ont rendu le raisonnement plus difficile. On a appris à vivre avec. On a ajouté de l’observabilité, des traces corrélées, des métriques. Comprendre prenait plus de temps, mais restait possible.
Puis l’IA générative est entrée dans les architectures. Pas comme un outil périphérique. Pas comme un assistant isolé. Comme un composant à part entière du système.
Et là, quelque chose a changé de nature.
Le moment où la chaîne causale se brise
Un LLM ne prend pas une décision au sens logiciel. Il génère une sortie statistiquement cohérente à partir d’un contexte partiel, reconstruit dynamiquement, influencé par un modèle probabiliste dont le comportement exact n’est jamais totalement figé. Tant que cette sortie reste cantonnée à de la génération de texte ou à de l’assistance humaine explicite, le risque est contenu.
Le basculement se produit quand cette sortie devient un maillon d’un flux distribué.
Un système classique, même complexe, reste lisible dans son enchaînement.
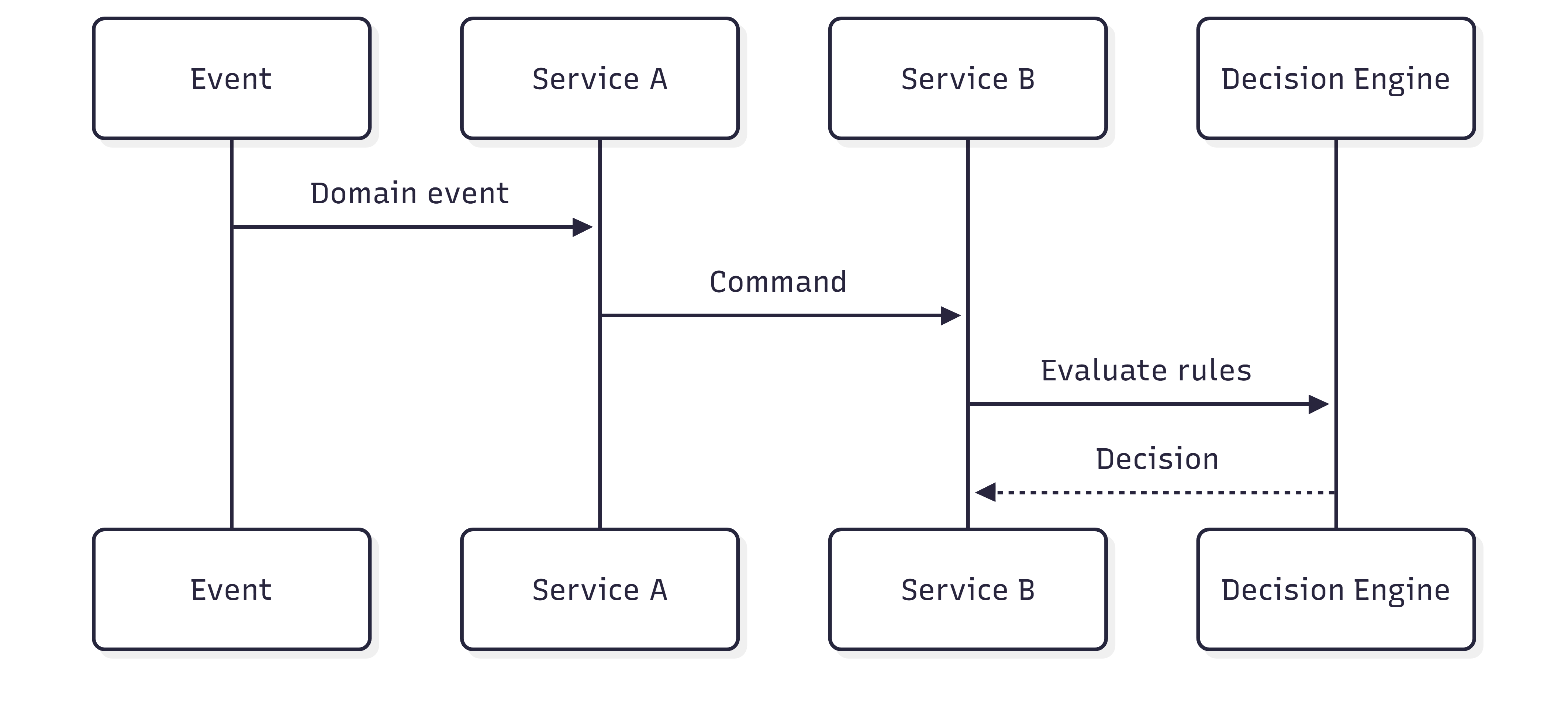
Chaque étape est déterministe. On peut rejouer le scénario. On peut expliquer pourquoi la décision a été prise. On peut la contester, l’ajuster, la corriger.
Insérons maintenant un LLM dans la chaîne, avec une intention parfaitement légitime : enrichir le contexte, analyser une situation, améliorer la qualité de la décision.
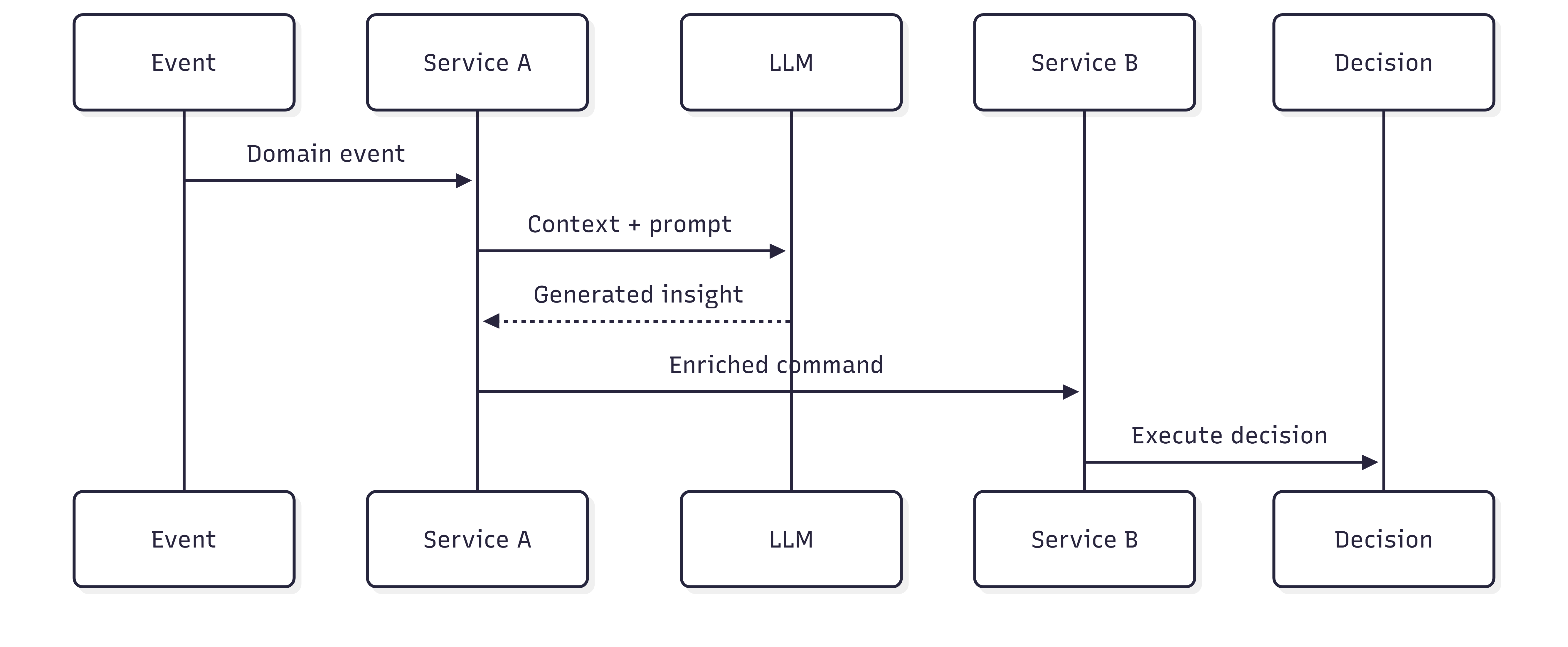
À cet instant précis, la chaîne causale se fissure.
La décision finale dépend d’un texte généré. Ce texte dépend d’un prompt. Ce prompt dépend d’un contexte reconstruit à l’instant T. Le modèle peut avoir évolué depuis la veille. Deux exécutions fonctionnellement identiques peuvent produire des résultats légèrement différents. Pas suffisamment pour alerter. Suffisamment pour orienter autrement une trajectoire métier.
Quand “ça marche” devient dangereux
Quand un incident survient, l’observabilité est là. Les traces sont complètes. Les logs sont propres. Mais la question centrale reste sans réponse satisfaisante : pourquoi cette décision là, et pas une autre ?
C’est ici que “ça marche” devient dangereux.
Le système ne tombe pas. Les métriques sont bonnes. La valeur est au rendez-vous. L’IA est perçue comme une amélioration incrémentale, pas comme une rupture architecturale. La confiance s’installe, lentement, presque mécaniquement.
Le problème n’apparaît que lorsqu’un humain demande une explication comme « Pourquoi ce ticket n’a pas été priorisé ?« , « Pourquoi ce client a été classé à risque ?« , « Pourquoi cette alerte n’a jamais été remontée ?« .
La seule réponse honnête devient floue. On peut montrer le prompt ainsi que la réponse du modèle. On peut aussi expliquer le fonctionnement général. Mais impossible d’expliquer la décision comme on expliquait une règle métier.
On ne pourra pas la justifier de manière déterministe, ni la rejouer à l’identique.
Alors le développeur ne pourra pas défendre cette décision sans raconter une histoire a posteriori.
À ce stade, l’observabilité ne suffit plus. Elle montre ce qui s’est passé, pas pourquoi c’était acceptable.
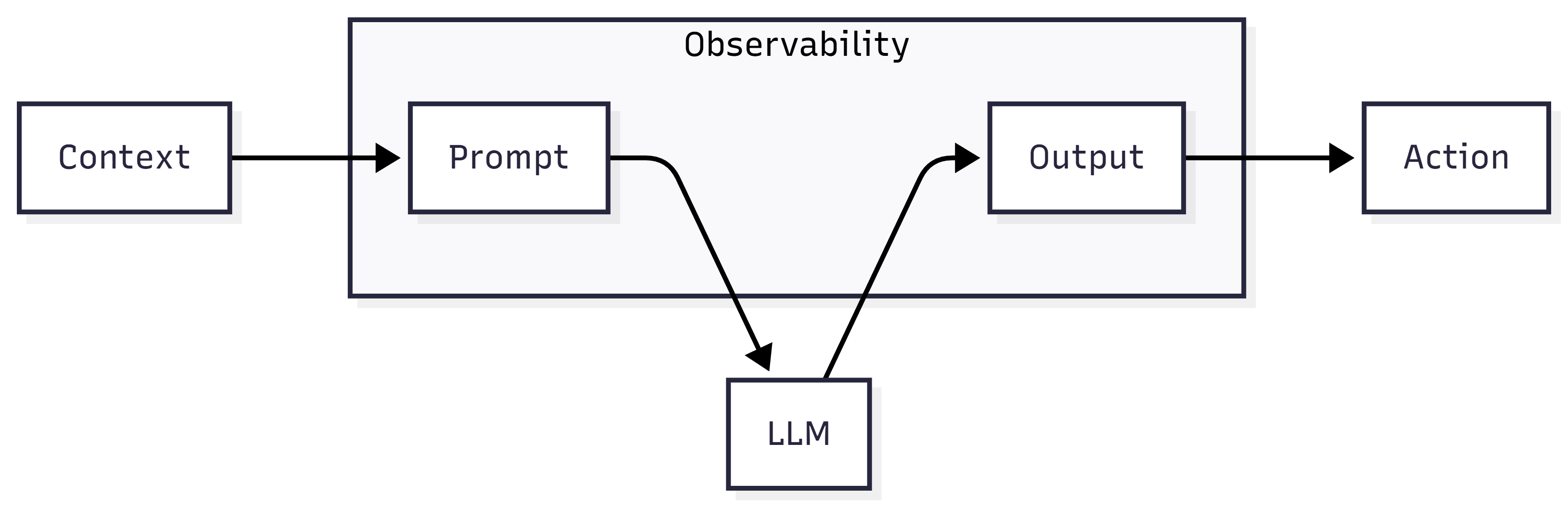
L’espace invisible entre le prompt et la sortie reste irréductible. Aucun log ne capture l’espace statistique où la décision a réellement émergé.
L’illusion du contrôle
Une illusion s’installe alors. On versionne les prompts, on logue les réponses, on trace les appels et on a l’impression de reprendre le contrôle. En réalité, on documente l’opacité sans la réduire.
C’est souvent à ce moment qu’apparaît l’argument le plus trompeur : la décision n’est pas bloquante, l’humain valide.
Une décision assistée mais non explicable devient de fait une décision automatisée. L’humain valide parce que le système fonctionne et le volume de données est trop important. Contester lui demandera plus d’effort que d’accepter.
Progressivement, l’IA ne conseillera plus. Elle orientera. Puis elle décidera sans jamais porter la responsabilité.
Une bonne décision n’est pas toujours la plus logique
Il y a pour moi une dimension encore plus profonde, souvent absente des discussions techniques.
Une bonne décision n’est pas nécessairement la plus logique.
Dans un système logiciel, on confond facilement cohérence et justesse.
Si les règles sont respectées, les données sont correctes et le résultat est reproductible, alors la décision est jugée bonne.
C’est une vision rassurante, parce qu’elle est purement technique.
Dans le monde réel, une décision est aussi jugée selon son acceptabilité sociale. De la manière dont elle est perçue. De ce qu’elle dit implicitement à ceux qui la subissent. Elle doit être acceptable pour un client, pour une équipe, parfois pour un juge. Pas seulement correcte sur le plan logique.
Un LLM peut produire une réponse parfaitement cohérente, statistiquement pertinente, alignée avec le contexte fourni. Et pourtant générer une décision humainement inacceptable. Pas choquante, pas absurde, juste déplacée et Froide.
Déconnectée de ce que personne n’a jamais formalisé explicitement.
Le système n’y voit aucun problème, la logique est respectée et la décision est optimale. Par contre, l’humain, lui, ressent immédiatement que quelque chose cloche.
Et c’est précisément là que l’ingénieur se retrouve désarmé. Il ne peut pas expliquer pourquoi la décision est acceptable, parce qu’elle ne l’est pas. Il ne peut pas expliquer pourquoi elle a été prise, parce qu’il n’existe aucune règle explicite à invoquer.
Alors, il ne reste que le modèle, le prompt, et un raisonnement probabiliste qui ne convainc personne.
Le contexte implicite que l’IA ne peut pas capter
Cette dérive est renforcée par une tentation universelle, quel que soit le métier. Si une tâche peut être automatisée, alors elle doit l’être. Si une décision peut être assistée, alors elle finira par être remplacée.
L’IA cristallise cette tentation. On commence par dire qu’elle aide puis qu’elle accélère, et on finira par dire qu’elle fiabilise. Et, sans rupture visible, on lui confie des responsabilités humaines. Non par idéologie, mais par confort. Parce que ça marche.
Le problème n’est pas la qualité des prompts. Même le prompt le mieux rédigé, même enrichi de données métier, ne capturera jamais le contexte implicite partagé par un corps social. Ce contexte n’est écrit nulle part. Il se transmet par l’expérience, par les échanges informels, par les non-dits, par la compréhension tacite de ce qui est acceptable, déplacé ou risqué.
Aucune entreprise ne fonctionne uniquement sur des règles explicites. Elle fonctionne sur un équilibre fragile entre ce qui est formalisé et ce qui est compris sans être dit.
Plus une organisation se repose sur l’IA pour décider, plus elle s’éloigne de ce contexte implicite. Elle commence à opérer selon une logique interne cohérente, optimisée, mais progressivement déconnectée du corps social dans lequel elle évolue. Les indicateurs restent bons. Puis apparaissent des incompréhensions, un malaise diffus, une perte de confiance client difficile à mesurer.
Ce n’est pas que l’IA a mal décidé. C’est qu’elle a décidé sans appartenir au groupe.
L’IA n’est pas dangereuse parce qu’elle se trompe
L’IA n’est pas dangereuse parce qu’elle se trompe. Elle est dangereuse quand elle a raison d’une manière que personne n’accepte. Quand elle devient le cœur silencieux de décisions qu’on ne sait plus expliquer, ni assumer.
Un LLM est remarquable pour explorer, résumer, proposer, challenger. Il est profondément inadapté lorsqu’on lui confie, même indirectement, le rôle de pivot décisionnel. Il doit rester en bordure du système et non dans son cœur transactionnel.
Le LLM doit produire des éléments lisibles par un humain, il ne doit pas déclencher des actions irréversibles sans responsabilité explicite.
Limiter l’IA à un rôle d’assistant n’est pas une posture conservatrice, c’est une manière de préserver l’ancrage social des systèmes que nous construisons.
Car le jour où “pourquoi” devient une question sans réponse acceptable, ce n’est plus un problème technique. C’est un problème de confiance.


