



Une API Web n’est pas un simple point d’accès à une base de données. Elle agrège des services, consomme des bus d’événements, maintient des caches en mémoire et expose parfois du streaming.
Elle vit dans un environnement asynchrone, distribué et instable par nature.
On continue souvent à la concevoir comme une succession d’appels. Un endpoint déclenche un traitement, qui déclenche un autre traitement, et ainsi de suite. Tant que les interactions restent simples, le modèle tient. Dès qu’on introduit du temps réel, des refresh concurrents, des invalidations, des événements entrants, le raisonnement devient plus fragile.
On ne modélise plus un flux cohérent, on orchestre des appels qui s’entrecroisent.
Rx.NET propose une autre approche. Plutôt que de piloter le système par des appels, on décrit l’évolution de son état à partir de flux. On ne s’intéresse plus uniquement à “quoi appeler”, mais à “comment l’état évolue dans le temps”.
Le réflexe des appels
On a pris l’habitude de raisonner nos APIs en termes d’appels. Un contrôleur appelle un service, qui appelle un repository, qui appelle un autre service. Ça fonctionne, tant que le monde est synchrone, ou qu’on accepte de ne pas trop regarder ce qui se passe dans le temps.
Le problème, c’est que nos systèmes ne sont plus synchrones. Ils vivent dans le temps. Ils reçoivent des événements, des invalidations, des refresh manuels, des timeouts, des ticks. Et on continue à les modéliser comme une succession d’appels.
Prenons un cas volontairement simple, une API Web qui expose des employés.
On veut servir un GET /employees rapide, cohérent, et proposer un GET /employees/stream en SSE pour les clients temps réel. Les données viennent d’un repository et d’un bus d’événements qui publie des EmployeeUpserted et EmployeeDeleted.
On ajoute un TTL pour forcer un refresh complet périodique, et un endpoint d’admin pour déclencher un rebuild.
En approche “appels”, on finit avec un cache en mémoire, des locks, un timer, des handlers d’événements qui patchent le cache, et un refresh complet qui remplace tout. Tant que tout arrive dans le bon ordre, ça tient. Sinon, le temps nous rattrape.
Le bug typique ressemble à ça :
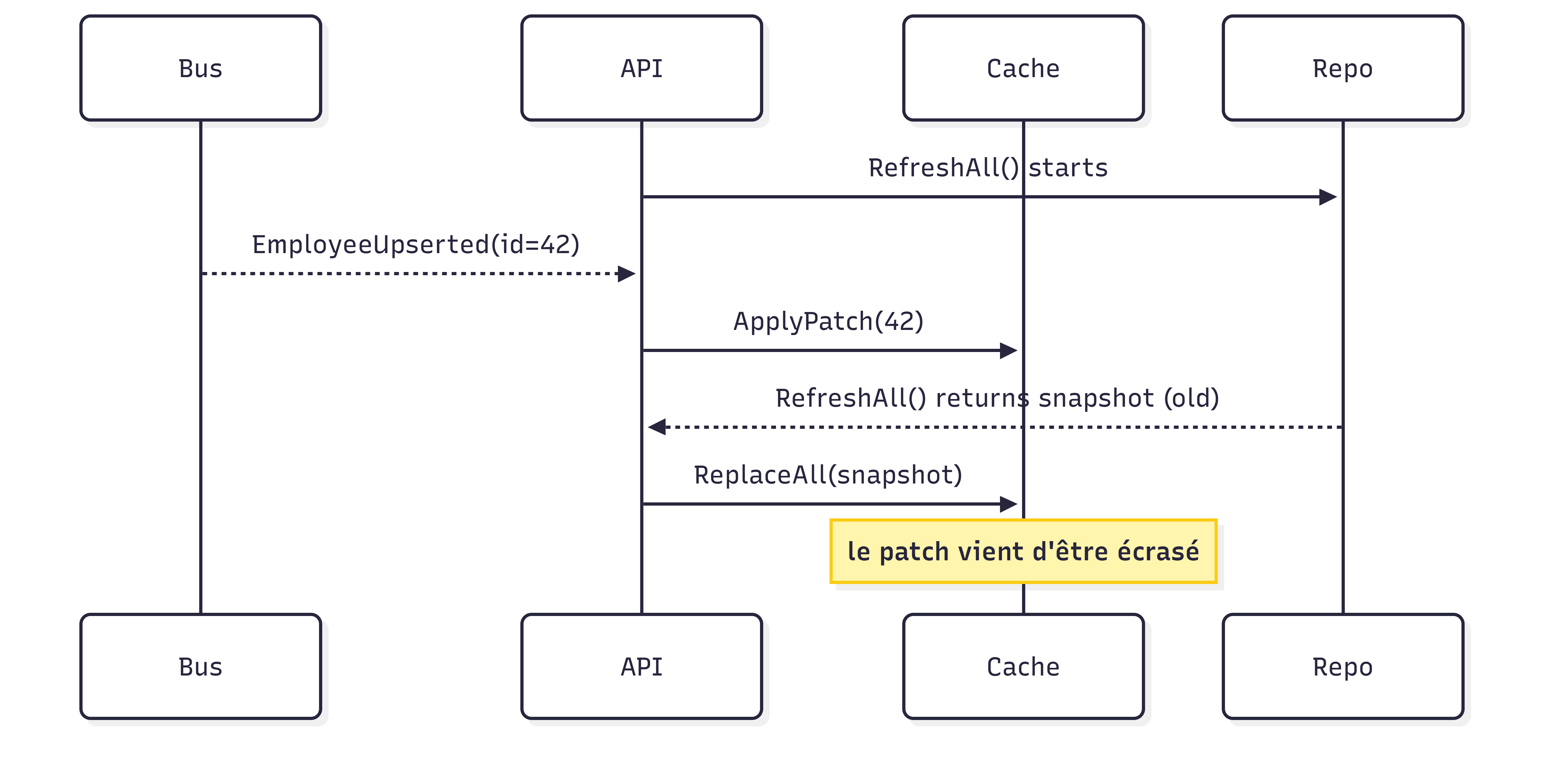
On a bien fait “les bons appels”. Juste pas dans le bon ordre. Parce que l’ordre réel est déterminé par le temps, et que le temps n’est représenté nulle part.
Introduire le temps dans le modèle
Avec Rx, on part d’un autre principe, tout ce qui fait évoluer l’état est un flux.
Les événements du bus sont un IObservable<EmployeeEvent>.
Le TTL est un IObservable<Unit>.
Le refresh admin est un IObservable<Unit>.
On ne déclenche plus des appels. On compose des sources temporelles.
Le modèle de domaine reste banal :
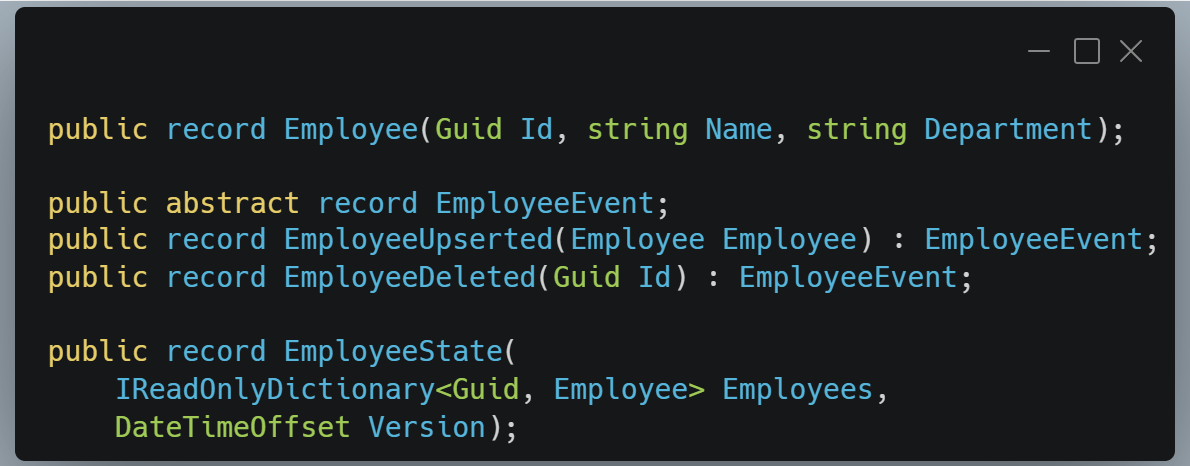
L’idée centrale est simple. On construit un flux d’EmployeeState qui représente l’évolution de l’état dans le temps. Les contrôleurs liront la dernière valeur.
Du refresh et des événements à un flux d’état
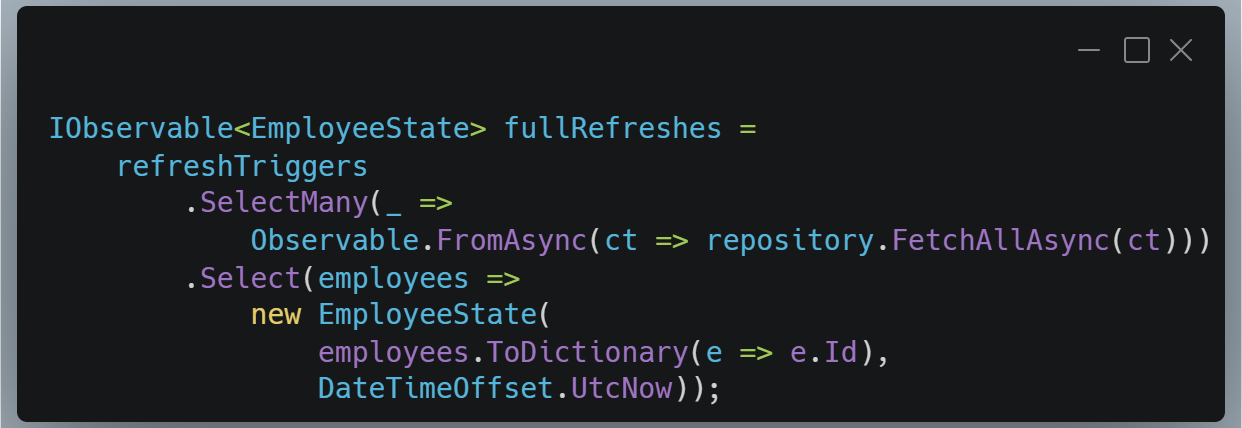
On commence par transformer nos triggers de refresh en flux de snapshots complets.
Les événements du bus deviennent des fonctions de transformation d’état.
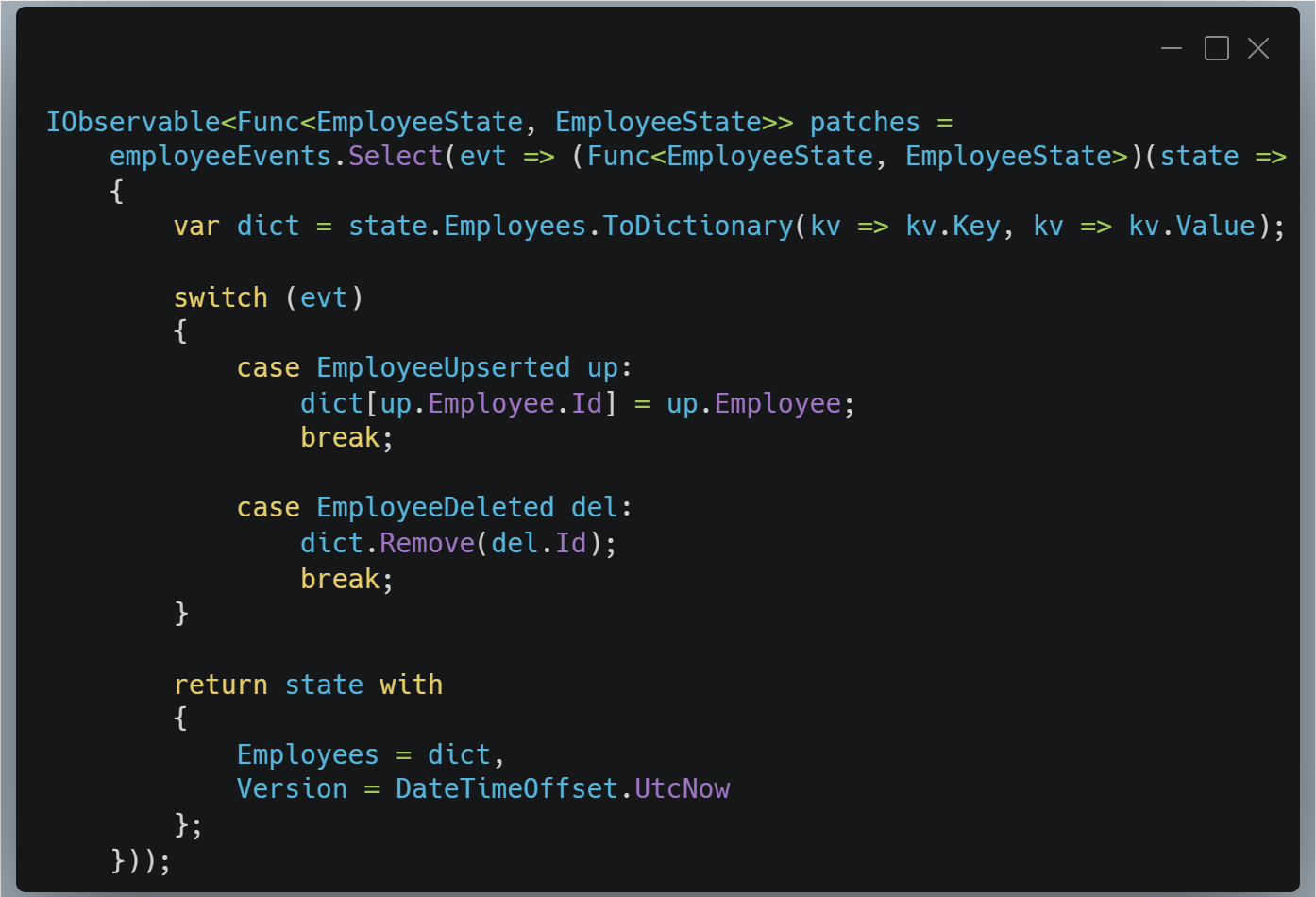
Le refresh complet est exprimé comme une transformation d’état. Il produira un nouvel état sans remplacer le cache.
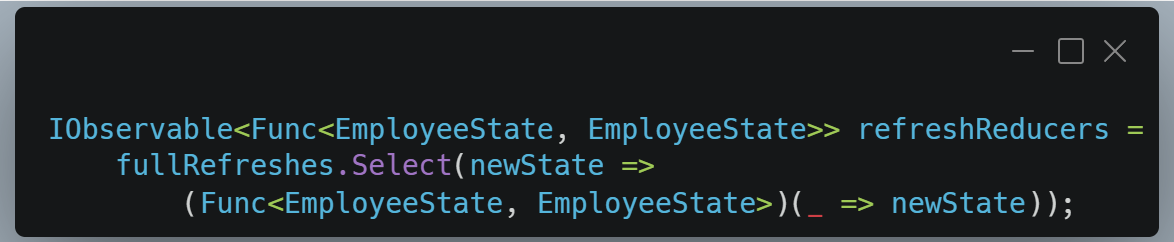
À ce stade, tout est homogène. On n’a plus des appels concurrents. Nous obtenons un flux unique de reducers et des fonctions qui décrivent comment l’état évolue.
On les fusionne avec la méthode « Merge ».

Puis on laisse Rx séquencer l’évolution via Scan.
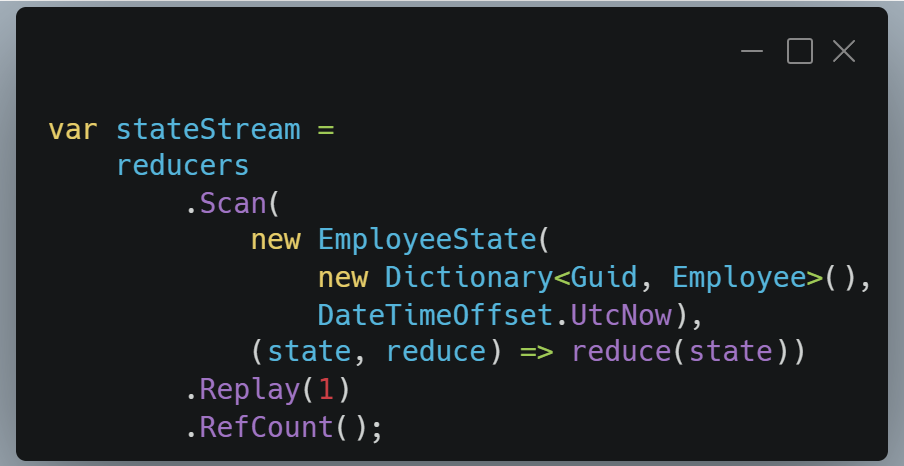
Chaque transformation est appliquée dans l’ordre d’arrivée des événements. Le temps est devenu explicite, linéarisé par le flux.
La topologie du système

Les contrôleurs HTTP lisent un état sans connaitre le détail du pipeline.
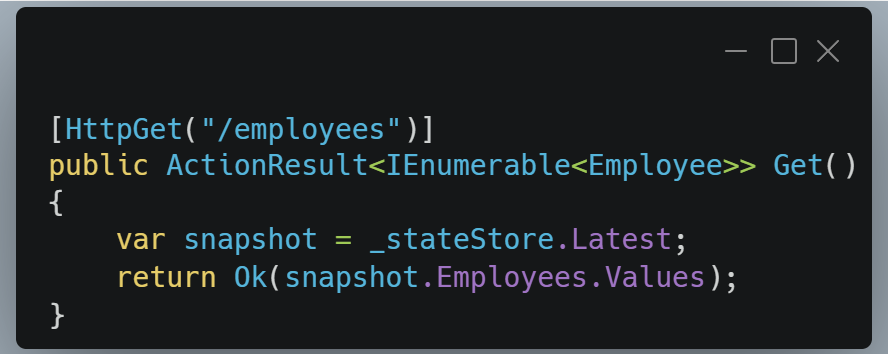
Pour le temps réel, on expose directement le flux.
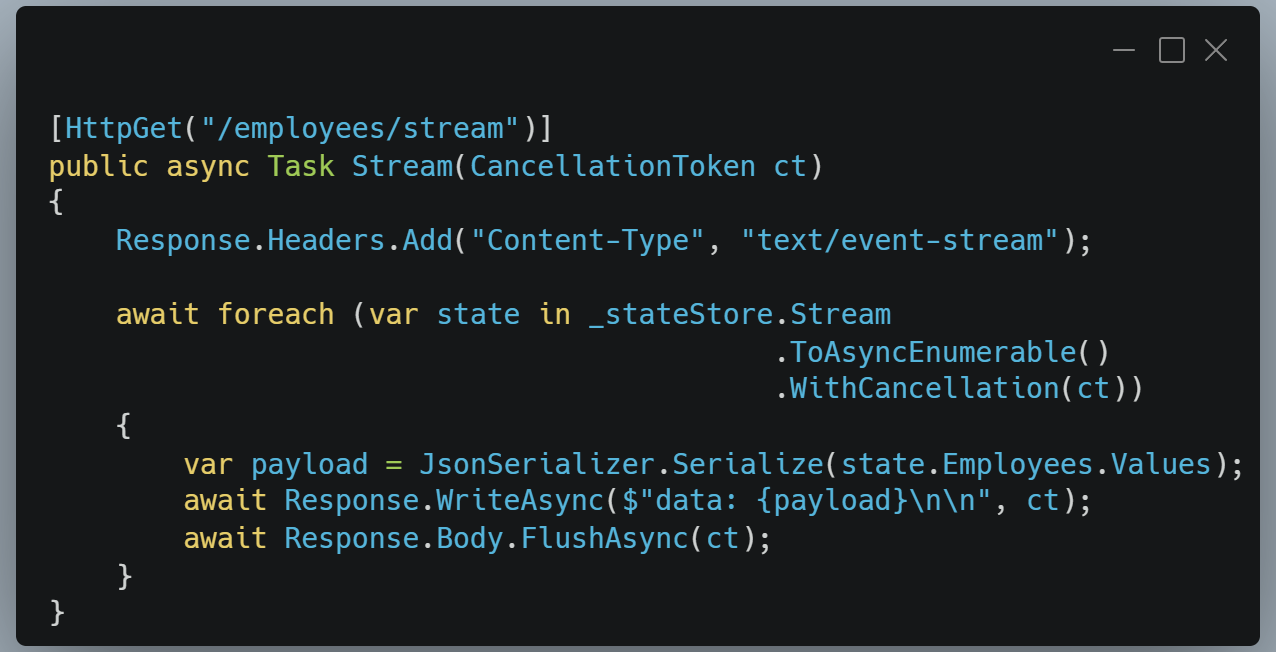
Pourquoi c’est adapté au temps réel
On ne gère plus un cache mutable piloté par des appels dispersés. La projection d’état est définit à partir du flux et le temps est intégré au modèle.
Quant au retry du refresh complet, il devient un opérateur. La logique de concurrence est maintenant structurée par le pipeline.
Rx unifie les Bus, webhooks, ticks, invalidations, heartbeats pour le temps réel.
Un IObservable qui émet une erreur se termine, si on ne veut pas que l’état meure au premier incident réseau, on doit l’exprimer explicitement, via Catch, Retry, ou une stratégie de repli. Là encore, le comportement temporel est explicite.
On ne remplace pas async/await. Une Task représente une valeur future unique. Un IObservable représente une succession de valeurs dans le temps. Pour une API qui doit agréger des sources continues et maintenir un état cohérent, la seconde abstraction colle mieux au problème.
Modéliser des appels, c’est penser en termes d’exécution.
Modéliser des flux, c’est penser en termes d’évolution.
Dès que le temps devient une dimension centrale du système, la seconde approche devient plus naturelle. Et dans une API qui consomme et expose du temps réel, ce n’est jamais un détail.
Télécharger le sample sur GitHub
https://github.com/xraboteu/RxNetApi
Pour aller plus loin, la documentation officielle de Rx.NET détaille l’ensemble des opérateurs et les patterns avancés (gestion des erreurs, scheduling, composition) :
https://reactivex.io/


